
Introduction
As a site reliability engineer, Kubernetes is the first tool I reach for in my homelab — whether it’s for family streaming services and game servers, learning new technologies, practicing for certifications, or developing product prototypes.
I’ve seen first-hand how Kubernetes’ declarative model lowers operational cost at scale, but bare-metal Kubernetes homelabs are still an emerging technology with limited tooling. I wanted to create an infrastructure as code framework to make bare-metal clusters as easy to provision and manage as any cloud provider, especially for a single sysadmin with limited time and resources.
That framework is based on Ubuntu Server 24.04 LTS and k3s. Ubuntu Server is a stable, familiar environment for most engineers who’ve worked with cloud infrastructure, and with an even smaller ubuntu-server-minimal variant in this release, it’s a great choice for a cloud-like environment where we can dedicate most of our focus to learning and building with k3s.
k3s is a tiny (<70mb), production-ready Kubernetes distribution that packages all of the necessary components for a cluster into a single binary. Compared to the stock distribution deployed by kubeadm, k3s is better suited for resource-constrained clusters; etcd has been swapped out for embedded sqlite requiring 512MiB RAM and a single core rather than 2GiB and two cores. It also offers a simplified YAML configuration schema and streamlined install and upgrade experience.
In this blog, I’ll demonstrate how to use GitOps techniques and SRE best practices to create YAML templates you can use to provision Kubernetes clusters at home, in a testable, repeatable and secure way. All you need is USB drive, a target system and half an hour.
Creating a Ubuntu Server installer USB
We’ll need to prepare our USB drive in order to gather some information about our hardware before we create our template.
- Download the Ubuntu Server 24.04.1 ISO
- Prepare your USB drive using unetbootin
- Direct download: unetbootin.github.io
- MacOS & Homebrew:
brew install unetbootin - Windows & Chocolatey:
choco install -y unetbootin
- Select
Diskimageas the target and load the ISO file you downloaded using the file dialog, your target USB drive from the dropdown, and hit OK.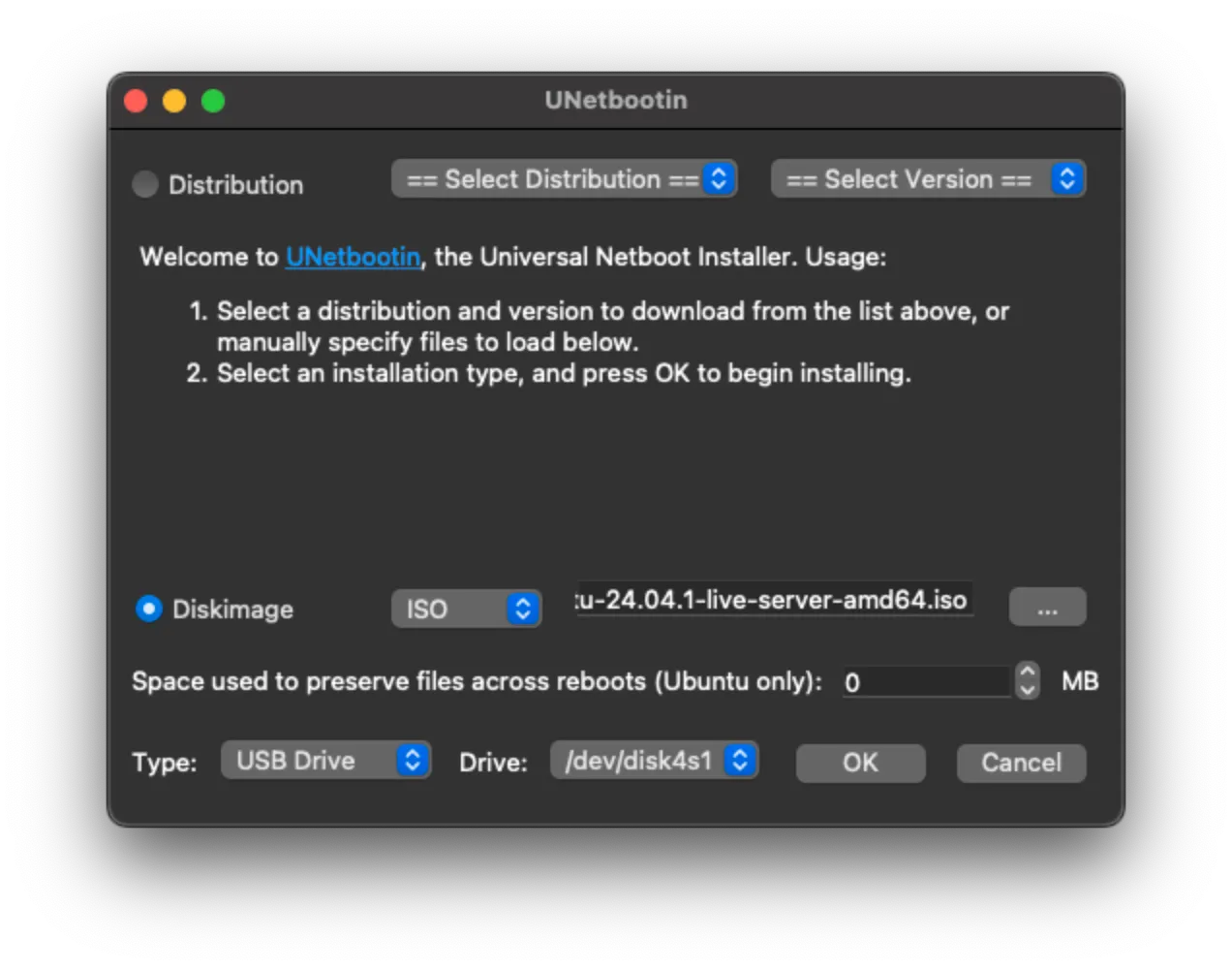
Cloud-init and the Ubuntu Autoinstaller
Subiquity, the Ubuntu Autoinstaller
The Ubuntu autoinstaller, also called Subiquity, allows us to perform a “zero-touch deployment” by supplying a remote endpoint where it will fetch its configuration from during the installation process. The docs can be daunting to navigate, so I’ve put together a guided tour of the information we need to proceed.
Creating autoinstall configuration is our jumping off point, demonstrating the basic format and common options of a complete user-data file. The autoinstall configuration reference manual is where you’ll find the complete list of configuration options available to the Ubuntu installer.
Cloud-init, the universal Linux configuration tool
Cloud-init is Canonical’s own industry stanadard solution for automatically configuring Linux instances. The cloud-init configuration schema offers a vast suite of customization options that we can use in tandem with Subiquity to define all of our customizations as YAML templates that we can commit to source control and use to provision bare-metal instances using a USB installer, just as easily as we can with any cloud provider.
The Subuquity autoinstall schema contains a special YAML key, autoinstall.user-data, which allows us to pass arbitrary cloud-init declarations. This is the key to the incredible flexibility of using declarative code to configure our infrastructure at every step. Cloud-init and autoinstall interaction explains how we can provide options from both the cloud-init schema and the Ubuntu autoinstall schema, using a commonly misunderstood format:
#cloud-config
# note: any cloud-init options provided at the top level will be applied to the *installer* environment
autoinstall:
version: 1
... # Ubuntu autoinstaller options go under `autoinstall`
user-data:
... # cloud-init options go under `autoinstall.user-data`
Why do we include an#cloud-configheader?When providing autoinstall via cloud-init, the autoinstall configuration is provided as cloud config data. This means the file requires a
#cloud-configheader and the autoinstall directives are placed under a top levelautoinstall:keyBasically, when supplying config from a remote endpoint, cloud-init kicks off the install. Unlike a config dropped onto your USB, it can accept more than just
#cloud-configfiles, so we use the header to indicate what type of configuration is being supplied.
Equipped with this information, we can put a basic template of our own together:
#cloud-init
autoinstall:
version: 1
# Update Subiquity, the Ubuntu server installer
refresh-installer:
update: yes
# Use a fully-updated minimal image for a cloud-like environment
source:
id: ubuntu-server-minimal
updates: all
# Install (non-free) codecs — required for transcoding
codecs:
install: yes
# Install all hardware drivers recommended by `ubuntu-drivers`
drivers:
install: yes
# enable SSH with password and ED25519 authentication — we'll secure this later
ssh:
install-server: yes
# internationalization settings
keyboard:
layout: us
timezone: geoip
locale: "en_US.UTF-8"
# default user (uid 1000)
identity:
name: ubuntu
host: ubuntu
# generate using `openssl passwd` or `mkpasswd`,
# default password is "ubuntu" — make sure you change this!
passwd: "$6$bhZARn1NjBXaQ.M.$JqHfRKB96fwRQQWNGH.tBxyECYY9rrbBeS8br84ccn4OSnC.7pyhvHunpobZ8fV8NCOIXasRGyZT4MCJWQYtM1"
Running the autoinstaller
Providing autoinstall configuration explains that we can supply this configuration as a cloud-config file by dropping it onto the install media, or our preferred method of hosting it on a local HTTP server whose address we’ll provide during installation. If we’ve set up our configuration file correctly, it will require just four lines of manual keyboard input and less than ten minutes.
Understanding Ubuntu’s install sequence
While Canonical docs describe how line arguments can be used to pass our configuration as a command line parameter when booting into the installer, they are less clear about where in the installer to provide it. The quickstvart has instructions for using kvm virtualization, but nothing about bare-metal installations:
kvm -no-reboot -m 2048 \
-drive file=image.img,format=raw,cache=none,if=virtio \
-cdrom ~/Downloads/ubuntu-<version-number>-live-server-amd64.iso \
-kernel /mnt/casper/vmlinuz \
-initrd /mnt/casper/initrd \
-append 'autoinstall ds=nocloud-net;s=http://_gateway:3003/'
If you haven’t worked with Linux VMs extensively, this syntax will seem opaque, and I wasn’t able to find a good explanation of the meaning of this code in Canonical’s docs. In fact, this snippet is from a thread on the Ubuntu forums that hasn’t been updated much since the autoinstaller was introduced in Ubuntu 20.04!
Let’s break down what’s happening here so it doesn’t remain folk knowledge, and then we’ll translate this into a format that the Ubuntu bootloader will accept.
The GRUB2 bootloaderGRUB2 (or GRUB) is Ubuntu’s default bootloader. In bare-metal scenarios, this is our interface for configuring how the autoinstall process is kicked off. GRUB passes the arguments to the kernel, which are then picked up by Subiquity.
- Lines 1-3: Start a VM with a previously downloaded Ubuntu installer ISO
- Line 4:
-kernelloads/casper/vmlinuz, a compressed, bootable Linux image from the mounted installer. Equivalent to the GRUB2 command,linuxin bare-metal scenarios. - Line 5:
-initrdloads/casper/initrdas the initial RAM state for the installer. Equivalent to theinitrdGRUB command. - Line 6:
-appendpasses arbitrary kernel arguments. When using GRUB, they will instead appear after/casper/vmlinuz.autoinstall, searched for by the Ubuntu installation backend, called Subiquity, skips a confirm dialogue on destructive disk actions.dsordatasourceindicates which source or cloud provider to retrieve configuration from.nocloud(sometimes appears asnocloud-net; this is legacy syntax removed in Subiquity 23.3) is the only data source relevant to us.sorsourcecontains the URL of a filesystem, HTTP, or FTP source.
From the datasources/nocloud page in cloud-init’s docs, we can see that it accepts four input files at the source endpoint: user-data, meta-data, vendor-data, and network-config.
The user-data and meta-data files must be present at the URL we provide, or the autoinstall process will be skipped and you’ll be booted back to the installer menu. vendor-data and network-config are optional, despite what the docs say.
Here’s what this looks like in grub.conf syntax:
menuentry "Auto Install Ubuntu Server" {
linux /casper/vmlinuz autoinstall "ds=nocloud;s=http://_gateway:3003" ---
initrd /casper/initrd
}
Because GRUB uses a modified BASH syntax, the ; (semicolon) between the cloud-init arguments must be escaped, or the entire string must be quoted as you see here.
Putting it together
- From the directory containing your
user-dataandmeta-datafiles, runpython http.server 8080. Obtain your LAN IP address usingip addr(Linux) orifconfig(MacOS). - Boot the target machine into the installer by selecting it under the boot options in your BIOS.
- Hit
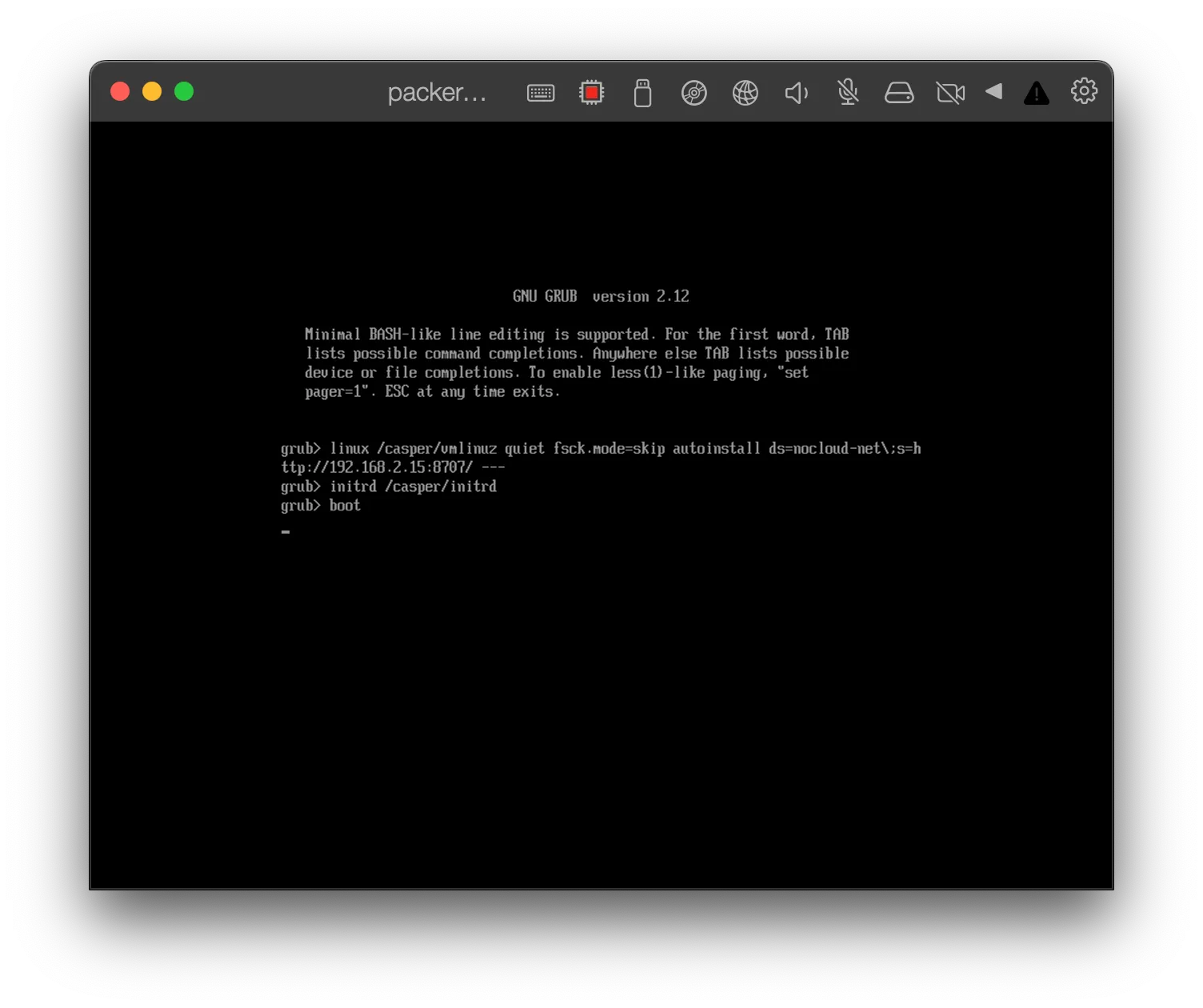
cto enter the command line. Enter thelinuxandinitrdcommands, followed byboot, replacing the HTTP URL with the IP and port we obtained in step 1. It should look something like this:
linux /casper/vmlinuz autoinstall "ds=nocloud;s=http://<HOST IP>:<HTTP PORT>/" ---
initrd /casper/initrd
boot
- Wait for the process to complete. If our installer executed correctly, we will see the machine reboot several times before reaching a login prompt. If you see an error message or you’re kicked back to the Ubuntu installer menu, you know that the configuration is invalid or one of your commands failed with a non-zero exit code.
Installing K3s with cloud-init
Now that we’re familiar with how to use the autoinstall schema, we can start employing cloud-init’s advanced options to install K3s during first boot.
Advanced user identity configuration
For the first iteration, we’ll operate the cluster as root over SSH. We’ll use cloud-init’s users: directive to import our authorized public keys from Github. This handy feature allows us to use Github as a kind of SSH identity provider, providing access to all of our machines using the same keys we sign code with. user-data.users is mutually exclusive with identity, so only include one.
user-data:
users:
- name: root
ssh_import_id:
- gh:<GitHub ID>
Running post-install commands
Next, we’ll use the runcmd directive to run the k3s install script during first boot, which will set our cluster up to run as a systemd system service. This means that there are no extra steps to start the k3s agent during boot, unlike when we run k3s as an unprivileged user, as we’ll see later in the series. It also means that starting and stopping the cluster requires root.
autoinstall:
user-data:
runcmd:
- |
curl -sfL https://get.k3s.io | sh -s -
We could have given unprivileged users permission to read /etc/rancher/k3s/k3s.yaml by passing K3S_KUBECONFIG_MODE="644" before sh in the snippet above, but this would be very insecure. Using GitHub private keys to secure access to root isn’t much better, but we’ll improve our security posture incrementally throughout the series.
Accessing the cluster
When we run our installer again, we should find that our node’s Kubernetes API is available on port 6443. Let’s confirm:
ssh root@<K3S NODE IP> k3s kubectl cluster-info
Now let’s copy our kubeconfig back to our operator machine:
scp root@<K3S NODE IP>:/etc/rancher/k3s/k3s.yaml ./kubeconfig.yaml
The kubeconfig file pulled from our k3s node will be pointing to localhost, so we need to replace it with the node’s actual IP address. To do this, we’ll use yq, which is available in most package managers.
yq e '.clusters[].cluster.server = "https://<NODE IP>:6443"' -i ~/kubeconfig.yaml
Now let’s confirm remote access to the Kubernetes API:
KUBECONFIG=./kubeconfig.yaml kubectl cluster-info
Congratulations! 🥳 You now have a working Kubernetes cluster that you can start deploying and iterating on.
Next steps
In the next part of this series, we’ll dive deeper into customizing our template for specific hardware configurations, including RAID using ZFS and bonded ethernet connections. We’ll learn how to leverage our code as a true template for entire classes of physical or virtual machines, whose host-specific details get injected by nocloud-metadata-server during provisioning.
Thanks for making it this far — it’s my first blog, and every read is deeply appreciated. If you’d like to support my work, please consider endorsing a skill on LinkedIn, subscribing to my Patreon and YouTube for upcoming DevOps content, or sharing my job search.